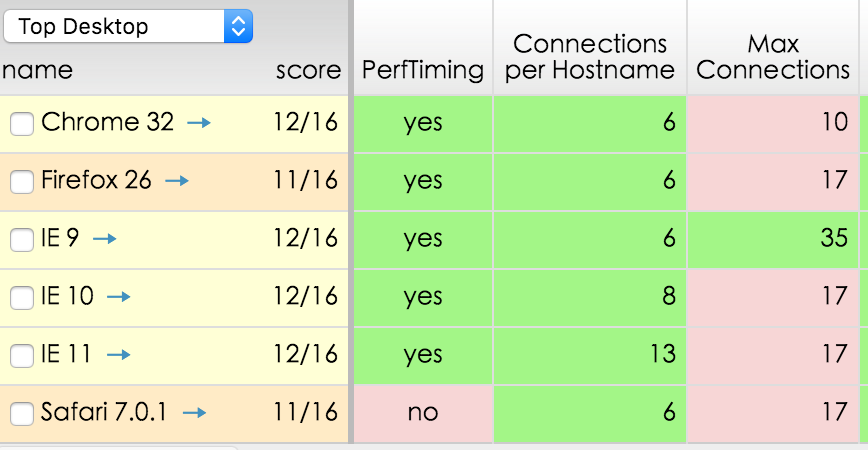
1、究其根本原因,在以前,服务器的负载能力差,稍微流量大一点服务器就容易就崩溃。 所以为了保护服务器不被强暴到崩溃,浏览器要对 max connections(最大并发数)进行限制。如果每个用户的最大并发数不限制的话,服务器的负载能力会大幅下降。
2、另外还有一个方面就是, 防止 DDOS 攻击。最基本的 DoS 攻击就是利用合理的服务请求来占用过多的服务资源,从而使合法用户无法得到服务的响应。如果不限制并发请求数量,后果,啊哦,你懂的。(有读者指出说这一点并不合理,没人发DDOS是通过浏览器去发的。查找文献后,我个人得出的结论是在一个 http 请求过程中的任何一步都可以被利用来进行 DDOS 攻击,那么放开并发限制,会不会间接导致被人利用进行 DDOS 攻击呢,个人观点,希望有人能继续提出指正!)

上面两张 dig 命令贴图中间出现了很多次 NS ,NS 即是 NameServer,大部分情况下又叫权威名称服务器简称权威。
什么是权威呢,通俗点讲其实是某些域的权威,也就是权威上面有这些域的最新,最全的数据,所有这些域的数据都应该以此为准(只有权威可以增删改这些域的数据),就像上面 dig com +trace 的结果可以看到,com 的权威是上面的 13 个根域。同理,所有的顶级域(cn、org、net 等等)的权威都是根域。Step1: 首先拿到 URL 后,浏览器会寻找本地的 DNS 缓存,看看是否有对应的 IP 地址,如果缓存中存在那就好了,如果没有,那就得向 DNS Server 发送一个请求,找到你想要的 IP 地址。
Step2: 首先他会向你的 ISP(互联网服务提供商) 相关的 DNS servers 发送 DNS query。然后这些 DNS 进行递归查询(recursive)。所谓的递归查询,就是能够直接返回对应的IP地址,而不是其他的 DNS server 地址。
Step3: 如果上述的 DNS Servers 没有你要的域名地址,则就会发送迭代查询,即会先从 root nameservers 找起。 即是假如你要查询 www.example.com ,会先从包含根结点的 13 台最高级域名服务器开始。
Step4: 接着,以从右向左的方式递进,找到 com. 然后向包含 com 的 TLD(顶级域名) nameservers 发送 DNS 请求。接着找到包含 example 的 DNS server。
Step5: 现在进入到了example.com 部分,即是现在正在询问的是权威服务器,该服务器里面包含了你想要的域名信息,也就是拿到了最后的结果 record 。
Step6: 递归查询的 DNS Server 接受到这 record 之后, 会将该record 保存一份到本地。 如果下一次你再请求这个 domain 时,我就可以直接返回给你了。由于每条记录都会存在 TLL ,所以 server 每隔一段时间都会发送一次请求,获取新的 record,
Step7: 最后,再经由最近的 DNS Server 将该条 record 返回。 同样,你的设备也会存一份该 record 的副本。 之后,就是 TCP 的事了,下面是一张萌萌的简化图:
到这里,我们大致就可以梳理一下,迭代查询的过程如下:
TTL 是 Time To Live 的缩写,该字段指定 IP 包被路由器丢弃之前允许通过的最大网段数量。TTL 是 IPv4 包头的一个 8 bit 字段。
简单的说它表示 DNS 记录在 DNS 服务器上缓存时间。
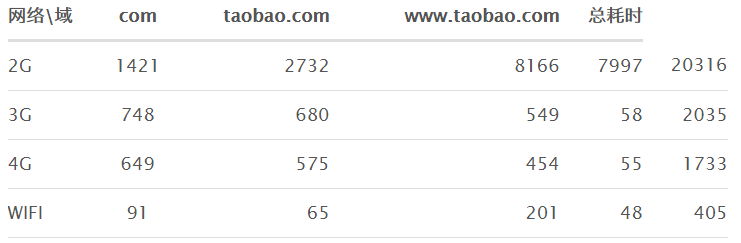
扯了这么多 http 请求, DNS 解析,回到正题域名收敛上,从上面可以看到,DNS 解析其实是一个很复杂的过程,在 PC 上,我们采用域名发散策略,是因为在 PC 端上,DNS 解析通常而言只需要几十 ms ,可以接受。而移动端,2G 网络,3G网络,4G网络/wifi 强网,而且移动 4G 容易在信号不理想的地段降级成 2G ,通过大量的数据采集和真实网络抓包分析(存在DNS解析的请求),DNS的消耗相当可观,2G网络大量5-10s,3G网络平均也要3-5s(数据来源于淘宝)。 下面附上在 2G,3G,4G, WIFI 情况下 DNS 递归解析的时间 (ms):

那么相比 http, SPDY 具体的优势在哪里呢:
1. 多路复用 请求优化SPDY 规定在一个 SPDY 连接内可以有无限个并行请求,即允许多个并发 HTTP 请求共用一个 TCP会话。这样 SPDY 通过复用在单个 TCP 连接上的多次请求,而非为每个请求单独开放连接,这样只需建立一个 TCP 连接就可以传送网页上所有资源,不仅可以减少消息交互往返的时间还可以避免创建新连接造成的延迟,使得 TCP 的效率更高。
此外,SPDY 的多路复用可以设置优先级,而不像传统 HTTP 那样严格按照先入先出一个一个处理请求,它会选择性的先传输 CSS 这样更重要的资源,然后再传输网站图标之类不太重要的资源,可以避免让非关键资源占用网络通道的问题,提升 TCP 的性能。
2. 支持服务器推送技术
服务器可以主动向客户端发起通信向客户端推送数据,这种预加载可以使用户一直保持一个快速的网络。
3. SPDY 压缩了 HTTP 头
舍弃掉了不必要的头信息,经过压缩之后可以节省多余数据传输所带来的等待时间和带宽。
4. 强制使用 SSL 传输协议
Google 认为 Web 未来的发展方向必定是安全的网络连接,全部请求 SSL 加密后,信息传输更加安全。
看看 SPDY 的作用图:
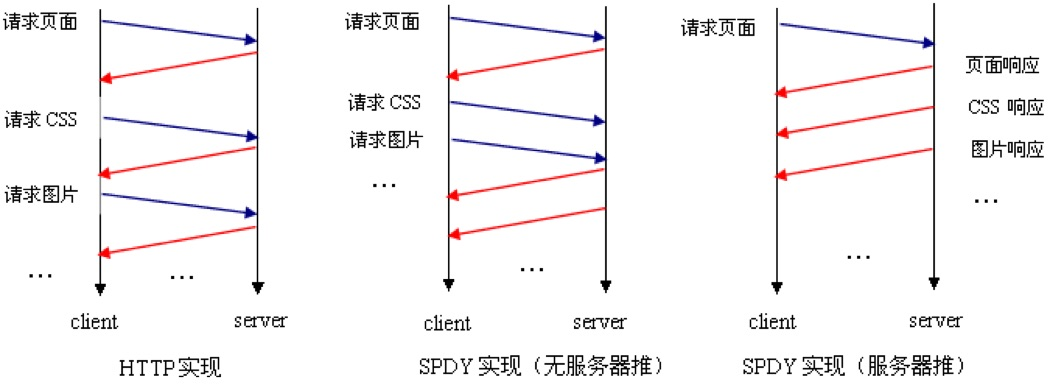
SPDY 协议在性能上对 HTTP 做了很大的优化,其核心思想是尽量减少连接个数,而对于 HTTP 的语义并没有做太大的修改。
具体来说是,SPDY 使用了 HTTP 的方法和页眉,但是删除了一些头并重写了 HTTP 中管理连接和数据转移格式的部分,所以基本上是兼容 HTTP 的。
- Google Chrome 和 Chromium 已经支持 SPDY。
- Mozilla Firefox 自11.0开始内嵌支持 SPDY 。从 Firefox 13 开始默认开启对 SPDY 的支持。
- Opera 从12.10开始支持 SPDY。
- Internet Explorer 11 开始支持 SPDY。
写到这里,好想继续往下写 HTTP/2 ,因为 HTTP/2 的前身即是 SPDY 协议,但是感觉本文的内容已经很充实了,内容也很多,就不再继续往下,内容很多,希望有人能够耐心读完,对一些网络基础知识很好的巩固效果。